The Continuous Causal Optimization Manifesto

The Continuous Causal Optimization Manifesto
By Brenden Delarua, co-founder, Stella Growth Intelligence
In January, a brand runs a rigorous geo holdout on Meta prospecting.
The result comes back: 72% incremental. Leadership is thrilled. The CMO presents it to the board. Budget doubles.
By April, the winning creative is exhausted. CPMs are up 40%. A competitor has entered the auction with a war chest. Spend has scaled well past the level that was tested.
The true number is now closer to 35%.
Nobody notices. Attributed ROAS still looks healthy. The January test result is still pinned to the wall, still quoted in meetings, still feeding the budget model.
For the next six months, this brand spends seven figures optimizing against a number that no longer exists.
This is not a brand doing measurement wrong. This is a brand doing measurement right, by the current definition of right. They ran a real experiment. They got a real causal answer. They acted on it.
The answer just stopped being true, and nothing in their stack was built to notice.
That should bother you. It bothered me enough to write this.
The argument of this paper, in two sentences
The marketing industry spent the last five years discovering that attribution was wrong.
The next five years will be spent discovering that static incrementality is wrong too.
Everything that follows is in service of that second sentence. If you only remember three ideas from this paper, make them these:
- Attribution is correlation, and correlation is not a budget input.
- Static incrementality is dead. Every causal estimate starts decaying the moment it is measured.
- The next decade of marketing will be won by the companies feeding the best causal signal into AI systems.
The meeting that started this
I need to tell you how I got here, because this paper did not come from a research department. It came from a conference room.
Years before Stella existed, I was the marketing guy walking into a CFO meeting with a deck I was proud of. Blended ROAS of 4.2. Channel-level wins on every slide. Meta crushing. Google crushing. By every dashboard my team looked at, every day, we were printing money.
I had spent two days building that deck. I knew every number in it. I was not walking in to defend the budget. I was walking in to ask for more.
The CFO let me get through maybe four slides.
Then he shared his screen. One slide. Two lines. Ad spend going up and to the right. Contribution margin going down and to the right. Same time period as my deck.
"Walk me through this," he said.
I couldn't.
I want to be precise about what happened in that moment, because I've spent years thinking about it. I was not caught lying. Every number in my deck was real. The platforms really did report those conversions. The ROAS math really did compute. I was caught doing something worse than lying: I was confidently presenting numbers that had no causal connection to the business, and I didn't know it.
The dashboards said one thing. The P&L said another. And only one of those has to reconcile with a bank account.
I went back to my desk and started asking a question I had never seriously asked in my career to that point: if we turned this channel off tomorrow, how much revenue would actually disappear? Not attributed revenue. Actual revenue.
I didn't know. Nobody on my team knew. The platforms certainly weren't going to tell me; they were the ones being graded.
That question eventually became geo holdouts, then calibrated MMM, then Stella. But here's the part that matters for this paper: when I finally got causally rigorous answers, I assumed the problem was solved. Measure incrementality, apply the factor, done.
It took losing money a second way to learn that a causal answer has a shelf life. The first lesson cost me a CFO meeting. The second one cost real budget, deployed confidently against a test result that had quietly expired.
Being wrong with confidence is the most expensive thing a marketing team can do. I have now done it with correlational data and with causal data. This paper exists so you can skip both.
Enemy #1: Attribution
This war is already over. Attribution lost. Some teams just haven't gotten the memo, so let's keep the obituary short.
Attribution was built for an internet that no longer exists. Third-party cookies, persistent device IDs, stitchable click paths. GDPR, CCPA, and Apple's App Tracking Transparency dismantled that world piece by piece. The walled gardens closed their gates and started grading their own homework. Sum your platform-reported conversions across channels and you will routinely "convert" more customers than actually exist. Anyone who has reconciled platform dashboards against a finance P&L has seen it.
But privacy was never the real problem. The real problem is structural and it predates every cookie deprecation:
Attribution measures correlation. Businesses need causation.
Attribution answers: which touchpoints appeared near this conversion?
The business question is: which investments caused revenue that would not have happened otherwise?
These sound similar. They are not even close.
Attribution isn't wrong like a typo. It's wrong like a compass sitting next to a magnet. It confidently points somewhere, every time, and the direction has a systematic bias toward whatever is closest to the conversion.
Here is what that bias looks like with real stakes attached. The pattern below is drawn from multiple client engagements, with identifying details adjusted; it is also one of the most replicated findings in the published literature.[1] A brand spends years scaling branded search because it is their highest-ROAS line item. 8x, 10x, sometimes 12x attributed. Untouchable. Then they run a geo holdout: branded search turned off entirely in a set of matched markets.
Revenue in those markets barely moves. In some weeks, the holdout markets outperform.
The customers were searching the brand name because they had already decided to buy. The paid ad sat above the free organic listing and collected a toll on a road those customers were already driving. Attribution scored that toll booth as the best-performing asset in the company. The causal contribution was approximately zero, and possibly negative after the click costs. When researchers ran this exact experiment at eBay scale, they found the same thing: branded search spend was almost entirely non-incremental.[1]
Now invert it. A prospecting video plants a brand in someone's memory. Two weeks later they buy directly. No click, no tracked view, nothing to attribute. The ad gets nothing. Its causal contribution may have been everything.
When a CFO asks "what happens to revenue if we cut this channel 30%?", attribution cannot answer. It was never designed to. It can tell you what happened near a conversion. It cannot tell you what caused one.
The industry slowly figured this out. The smartest operators moved to incrementality: geo holdouts, lift tests, calibrated MMM. Counterfactual measurement. Real causal answers. Brands that adopted it routinely discovered that a large share of their attributed revenue was not incremental, and reallocated accordingly. This is not a fringe finding: large-scale field experiments at Facebook itself showed that attribution-based estimates routinely and substantially diverge from experimentally measured lift.[2]
That was genuine progress. It was also incomplete, in a way almost nobody is talking about, and the incompleteness is the entire reason this paper exists.
Enemy #2: Static Incrementality
Here is the most important idea in this paper. I am going to state it plainly and then attack it from every angle I have, because the industry has not internalized it and the cost of not internalizing it compounds every quarter:
Incrementality is not a fixed number. It is a moving target.
The incremental return of a channel is not a property of the channel. It is a property of the channel in a specific market state: a particular auction environment, creative mix, competitive landscape, seasonal demand level, and position on the saturation curve.
Change any of those conditions and the causal effect changes with them.
Those conditions change constantly.
Causal Decay
We call this Causal Decay: the process by which every incrementality estimate becomes less trustworthy over time.
Every causal estimate starts decaying the moment it is measured.
Causal Decay is not a measurement error. The test was right. The world moved. Six forces drive it, and at least three of them are acting on your account right now:
Creative fatigue. A winning ad's incremental impact erodes as its audience saturates. The campaign keeps reporting healthy attributed ROAS long after its causal lift has declined, because retargeting and brand familiarity keep harvesting conversions the creative is no longer generating. Attribution doesn't just miss the decay. It actively hides it.
Auction dynamics. CPMs move with competitor budgets, inventory shifts, and algorithm updates. The same dollar buys a different quantity and quality of attention in March than it did in January. When Meta ships a delivery update or a funded competitor enters your auction, your cost per incremental conversion moves whether you touched your account or not.
Seasonality. Prospecting spend in October builds demand that converts in November. The same spend in January lands on an exhausted audience. A holdout run in one season produces a factor that is simply wrong in another.
Competitive pressure. A competitor's aggressive launch can suppress your incrementality without any visible change in your own metrics. Their exit can inflate it. You are measuring your marketing inside a system you do not control.
Saturation. Incrementality is marginal, not average. The first $50K in a channel may be highly incremental while the next $50K returns a fraction of that. Scale spend 40% after a successful test and the factor you measured no longer describes the dollars you are now spending.
Mix interactions. Channels affect each other. Scaling top-of-funnel video changes the composition of your branded search demand, which changes branded search's incrementality. No channel's causal effect is independent of the others.
What decay looks like in an actual account
Theory is cheap, so here are two patterns we see over and over.
The retest shock. A brand tests Meta prospecting in Q1: 70% incremental. Clean test, well powered, matched markets. They retest the same channel in Q3, expecting confirmation. The result: 40%. Nothing was broken. Three things had changed. The hero creative that carried Q1 had been in market for seven months and its audience was saturated. A competitor had entered the auction in May and CPMs were up. And spend had scaled 60% past the tested level, deep into the flat part of the response curve. Each change was visible in isolation. Nobody connected them to the incrementality factor, because nothing in the stack was watching for the connection. For two quarters, every budget decision used 70% when reality was 40%. Run that error across a seven-figure channel and tell me measurement is a back-office function.
The scale-up collapse. A brand gets a strong geo test result and does exactly what a strong result invites: doubles the budget. Six weeks later, blended performance is sagging and nobody can say why, because attributed ROAS only dipped slightly. The answer is the difference between average and marginal. The test measured the average incrementality of the tested spend level. The new dollars were buying the marginal customer, far out on the saturation curve, at a fraction of the tested incrementality. The test result was true. It just wasn't true about the dollars they were now spending. They used a photograph of the channel at $300K a month to justify what the channel would do at $600K, and the photograph had nothing to say about that.
Both of these brands had causally valid measurements. Both lost money anyway. That is the signature of the static incrementality era: rigorous answers to yesterday's question, applied to today's budget.
The Incrementality Half-Life
Every causal estimate has what we call an Incrementality Half-Life: the time it takes for market conditions to drift far enough that the estimate is no longer safe to make budget decisions on.
Nobody knows their half-lives. That is the scandal.
Brands know their CAC to the dollar and their conversion rate to the second decimal. Ask them how long their last geo test result stays true and you get a shrug. For a stable channel in a quiet market, the half-life might be two quarters. For a creative-driven channel mid-scale-up in a contested auction, it might be six weeks. The brand treats both numbers as equally permanent, because both arrived in the same kind of deck with the same confidence interval.
Most marketing teams spend more time debating confidence intervals than expiration dates.
That's backwards. A perfect answer that expired three months ago is still wrong.
Your dashboard has a field for statistical significance. It has no field for "this number is no longer true."
You cannot photograph your way to a video
The industry's instinctive response to Causal Decay is to test more often. Quarterly becomes monthly. One geo test becomes a testing calendar.
That helps. It does not solve the problem, and it's important to understand why.
Periodic testing of any frequency still produces point-in-time estimates of a continuously changing quantity. A geo holdout is a photograph. Incrementality is a moving object. Take more photographs and you get a flipbook, expensive and still mostly blank between frames.
You cannot photograph your way to a video.
And calendar-driven testing has a deeper flaw: it spends your experimentation budget on ritual instead of uncertainty. You re-test the stable channel because it's Q3 and that's the schedule, while the channel that actually drifted three weeks ago sits unexamined because its turn isn't until Q4. The calendar doesn't know what changed. Calendars never do.
So sit with the uncomfortable question, because the rest of this paper depends on you feeling it rather than nodding at it:
Why are you using a six-month-old causal estimate to make tomorrow's budget decision?
You wouldn't trade stocks on a six-month-old price. You wouldn't set tomorrow's flight plan on last quarter's weather. You wouldn't price inventory on last year's costs. Marketing is the only function in the building that takes a decaying number, laminates it, and calls it ground truth.
Static incrementality was a worthy successor to attribution. It answered the right question. It just answered it once, framed the answer, and hung it on a wall while the world kept moving.
The machine spending your money
For most of marketing history, a stale number was a slow leak. Budgets moved quarterly, humans made the decisions, and a wrong estimate did its damage gradually.
Then the platforms took the wheel.
Over the past two years, Meta replaced its ad delivery system. Not tuned it. Replaced it. Andromeda rebuilt retrieval as an AI system co-designed down to the silicon, deciding which ads from billions of candidates even enter consideration for a given person.[3] Lattice consolidated hundreds of separate ranking models into one architecture that learns across every surface, with sequence learning that reads full customer journeys instead of point-in-time snapshots.[4] GEM, a foundation model trained at LLM scale across ads and organic behavior alike, now sits above the fleet and teaches every other model how to predict better, which is why media buying hacks die in days instead of quarters.[5] ARM, the newest layer, points at where this goes: LLM-grade intelligence applied to every auction in real time.[6] Google is walking the same road with Performance Max.
If you're reading this in 2031, the names will have changed. They were always going to. The names are not the point. The point is the direction, and the direction is one-way: the platforms are becoming autonomous, and every generation of the machinery is less auditable and less steerable from the campaign level than the one before it.
Meta already tells you this, in its own way. It openly warns advertisers about the breakdown effect: segment-level reporting is misleading, because delivery optimizes holistically and the breakdowns don't reflect how the system actually allocated.[7] Sit with that. The platform that grades its own homework is telling you not to read the grades too closely. The system has officially outgrown its own dashboard.
And the endgame is not subtle. Zuckerberg has said it out loud: a business comes to Meta, says what it wants to sell, sets a budget, and the machine does the rest.[8] Creative generated. Targeting handled. Click create, upload product photos, go. Every "loss of control" media buyers have complained about for five years is not drift. It is a straight line toward that world.
So here is the question that actually matters, and it's not "how do I adapt my campaign structure to this quarter's architecture."
When the platform makes every decision, what is left for the advertiser to be good at?
Three things survive:
- Creative. What the machine has to work with.
- Budget. How much it gets.
- Signal. What it is told to optimize toward.
Meta did not take away your levers. It revealed which ones were real.
Now watch what happens to the first lever. The same platforms automating delivery are automating creative: generated variations, auto-assembled formats, AI-written copy, with the stated goal of generating the ads themselves from your product catalog. The moment every advertiser's creative is produced and varied by the same generative systems, creative stops being a moat and becomes table stakes. Still necessary. No longer differentiating.
Picture the saturated categories first, because they're the leading edge. Supplements. Skincare. Apparel basics. Hundreds of brands selling functionally identical products, all using AI-generated creative, AI targeting, AI bidding, on the same platform, against the same customers. The barrier to entry approaches zero. Every account converges on the same playbook because the same machine is writing the playbook.
How does anyone win that market? Not with budget; the machine spends everyone's budget with the same efficiency. Not with targeting; there is no targeting. Not with creative volume; everyone has infinite creative.
You win with the one input that remains proprietary: what you teach the machine to value.
The Signal Quality Gap
These systems are extraordinarily good at maximizing whatever objective you feed them. That is precisely the danger.
Feed them platform-attributed purchase events and they will dutifully maximize attributed purchases. Which means they will gravitate toward the users easiest to attribute: existing customers, brand searchers, people already deep in consideration. A system that understands full purchase journeys is even more efficient at finding people already on the journey and stepping in front of them right before the finish line. The AI is not malfunctioning. It is succeeding at the wrong objective, with superhuman competence.
We call the distance between what the platform optimizes toward and what actually makes you money the Signal Quality Gap: the difference between platform-attributed conversions and true incremental profit. Every brand has one. Most have never measured it. The platforms have no incentive to close it, because the gap is invisible in their dashboards and the dashboards are theirs.
Your conversion feed is your strategy, as far as the algorithm is concerned. It does not read your positioning deck. It does not know your margin structure. It does not know that half the "purchases" it's celebrating came from customers who were coming anyway. It knows exactly one thing about your business: the events and values you send back. That feed is the entire interface between your P&L and a trillion-parameter optimization system.
Most brands are feeding that system raw attributed conversions. They have pointed the most powerful optimization machinery in commercial history at the wrong number, on purpose, every day, and they call it best practice.
Here is the thesis this era will be remembered for:
When every advertiser has access to the same platform AI, the advertiser feeding it the best causal signal wins.
Two supplement brands. Identical budgets, machine-generated creative on both sides, the same delivery infrastructure. They diverge on one input: one is sending incrementality-corrected, margin-weighted values, training the machine to find customers who would not have purchased otherwise. The other is sending raw pixel events, training the same machinery to find customers who were coming anyway, and paying full price for them.
Same algorithm. Different teachers. Different outcomes.
Why this outlives every acronym
Every architecture the platforms have shipped, and every one they will ship, has one constant: the system optimizes toward the events and values the advertiser sends back. Retrieval engines get rebuilt, ranking models get consolidated, foundation models get stacked on top, and every version still asks the advertiser the same question: what counts as success?
The machinery changes. The input contract doesn't.
Operating at the signal layer means you are not betting on an architecture. You are upstream of all of them. Campaign-level playbooks expire with every engineering blog post. Buyers adapt to each new system. Signal owners hand each new system a better objective on day one.
And note what the signal layer demands. Platform AI adapts in days. A causal correction based on a six-month-old test is a correction to a delivery pattern that no longer exists. A static incrementality factor feeding a dynamic optimizer is a car with a steering wheel that only turns once a quarter.
The machine learns continuously. Anything that steers it must measure continuously. There is no static version of winning this game.
Enemy #3: Reporting Culture
One more enemy before the answer, and this one lives inside your own building.
Most marketing measurement, including most good marketing measurement, ends in a report. A deck. A dashboard. A QBR slide that says "Meta prospecting: 70% incremental" with a green checkmark next to it.
Then everyone goes back to doing exactly what they were doing.
Reporting culture is the belief that measurement is complete when it has been communicated. It is why brands spend six figures on MMMs that live in slide decks. It is why incrementality results get presented, applauded, and never wired into a single platform setting. It is why a company can simultaneously have excellent measurement and terrible allocation.
Measurement that does not change behavior is a cost center with charts.
So here is the line this entire paper has been building toward:
The purpose of measurement is not reporting. The purpose of measurement is optimization.
If a causal insight never touches a budget, a bid, or a signal, you did not measure. You decorated.
Why nobody solved this
If static incrementality decays, and AI platforms punish stale signals, and reporting culture wastes whatever truth gets found, why hasn't anyone built the obvious fix?
Because the fix requires four different disciplines to operate as one system, and the industry sells them as four different products.
The experimentation vendors sell you tests. The MMM vendors sell you models. The analytics vendors sell you monitoring. The platforms sell you activation, pointed at their own attributed numbers. Each piece works. No piece, alone, survives contact with a moving market:
- Experiments alone give you point-in-time truth that silently expires.
- Models alone give you an elegant map anchored to nothing. An uncalibrated MMM is an opinion with confidence intervals.
- Monitoring alone tells you something changed but not what or why.
- Activation alone automates decisions against wrong numbers, faster.
Every failure mode of one piece is covered by another piece. Which means the answer was never a better test, a better model, a better dashboard, or a better integration.
The answer is the loop. But before we name it, one thought experiment.
The day static incrementality dies
Imagine Meta ships an update tomorrow morning.
Every campaign now optimizes on incrementality instead of attribution. Every campaign updates its incrementality estimate daily. Every campaign optimizes toward incremental profit, margin-weighted, at the marginal dollar.
Sit with that world for a minute.
Would you still run a geo test once a quarter and treat the result as truth until the next one? Of course not. Your own delivery system would be updating its causal view of your account every single day; a quarterly snapshot would be laughably behind your own ad account.
Would you still report platform ROAS to your CFO? Against what? The platform itself would be telling you what was incremental.
Would you still pay an agency a percentage of spend to manage campaign structures the machine no longer exposes?
Would you still have a measurement deck at all, or would measurement just be a live layer your budget tools read from, the way your treasury tools read exchange rates?
Here's the uncomfortable part. Nothing in that thought experiment changed your business. Your products, customers, margins, and competitors are all identical. The only thing that changed is that the measurement became continuous, causal, and connected to the spending. And the moment it did, your entire current operating model (quarterly tests, static factors, ROAS reporting, deck-driven decisions) became self-evidently absurd.
If you wouldn't run marketing this way in that world, why are you measuring it this way in this one?
The platforms are not going to ship that update, or if they do, they will grade their own incrementality the way they grade everything else: in their favor, inside their walls, invisible to audit. Nobody is coming to build your causal layer for you. The thought experiment doesn't describe a future Meta release.
It describes the system you should already be running.
Continuous Causal Optimization
We call that system Continuous Causal Optimization, and the simplest way to understand it is by what each era of measurement could tell you:
Attribution tells you what happened. Incrementality tells you what worked. Continuous Causal Optimization tells you what to do next.
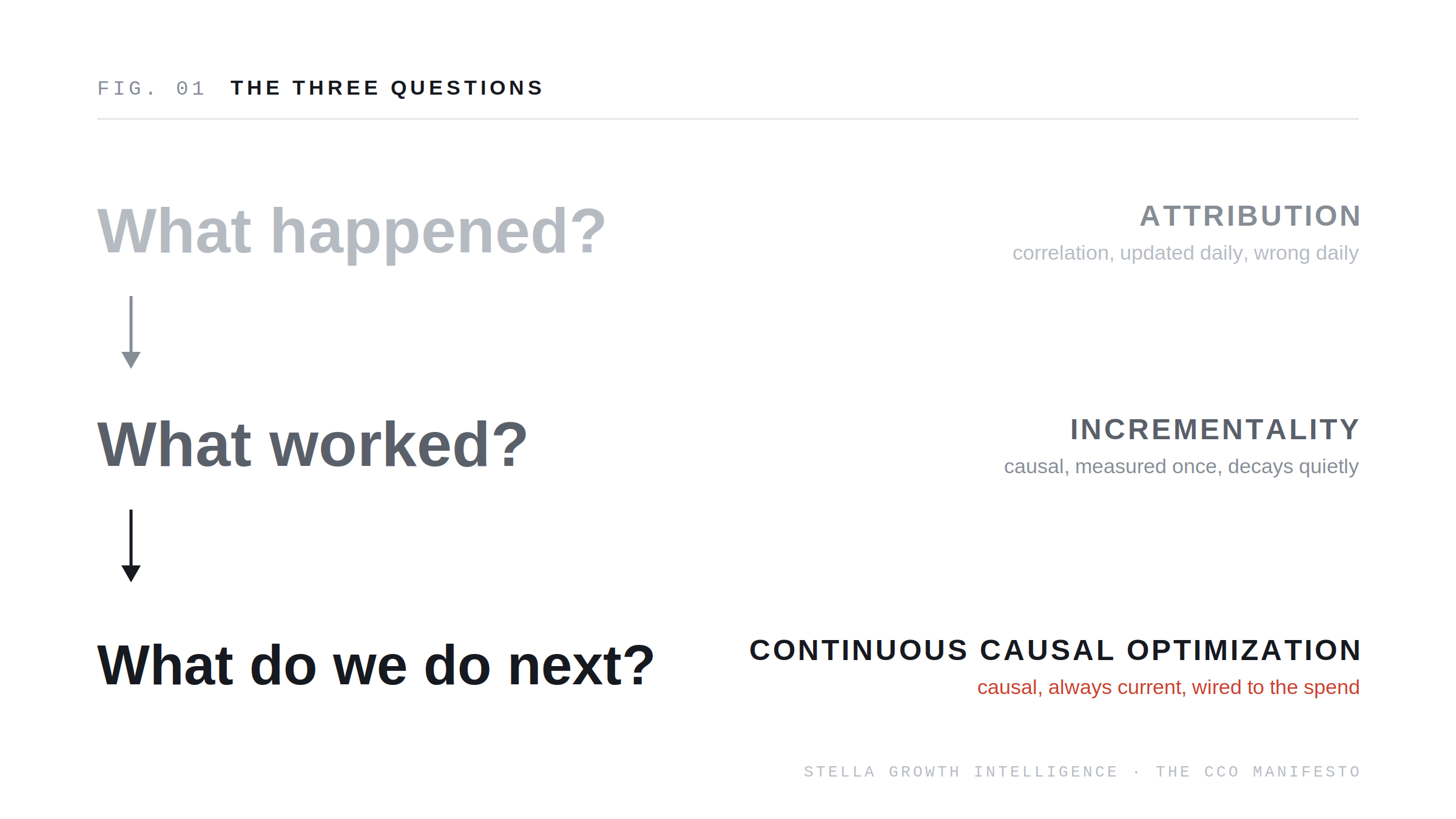
Formally: CCO is a measurement and optimization framework in which causal experiments, calibrated structural models, always-on drift detection, and automated signal activation operate as a single closed loop, so that every marketing decision is made against current causal truth instead of correlational attribution or expired test results.
Three words, three commitments:
- Continuous. Measurement is live infrastructure, not a quarterly event. Estimates update as conditions change, and the system knows when they've drifted.
- Causal. Every number is grounded in a counterfactual. Never "what touched this conversion?" Always "what would have happened without this spend?"
- Optimization. The loop closes. Causal truth flows back into budgets and into the AI systems inside the platforms. Nothing terminates in a slide.
The four layers of CCO
A complete CCO implementation has four layers. Together they form the infrastructure that sits between your business outcomes and the platforms spending your money.
Layer 1: Experimental Truth. Geo holdouts, lift tests, audience holdouts, budget step tests. Geo experiments measure real business outcomes at the market level, which makes them immune to cookie loss, ATT, modeled conversions, and the breakdown effect.[9] This layer is the anchor; a causal system without experiments is a model grading its own homework, and we already have platforms for that.
Layer 2: Structural Learning. You cannot run a holdout on every channel every month. Modern Bayesian MMM extends experimental findings into a full map of the mix: contributions, response curves, saturation points, channel interactions.[10] The discipline that makes this layer honest is calibration: Layer 1 results anchor the model to ground truth instead of letting it float on correlational fit.[11]
Layer 3: Continuous Estimation. The layer the rest of the industry has not built, and the one this entire paper has been arguing for. Always-on causal monitoring maintains dynamic incrementality factors and runs drift detection that flags when reality diverges from what the calibrated models predict.[12] This is where Causal Decay gets caught instead of compounding, and where Incrementality Half-Lives stop being unknowable. When drift is detected, the system widens its uncertainty and recommends the specific experiment that would resolve it. Your testing budget stops following a calendar and starts following uncertainty.
Layer 4: Activation. Causal truth flows back into the operational stack: incrementality-corrected, margin-weighted conversion values stream to the platforms through conversions APIs and value rules, budgets shift toward marginal incremental contribution within guardrails, and reverse causal attribution translates channel-level truth back down to the campaign level operators actually manage.
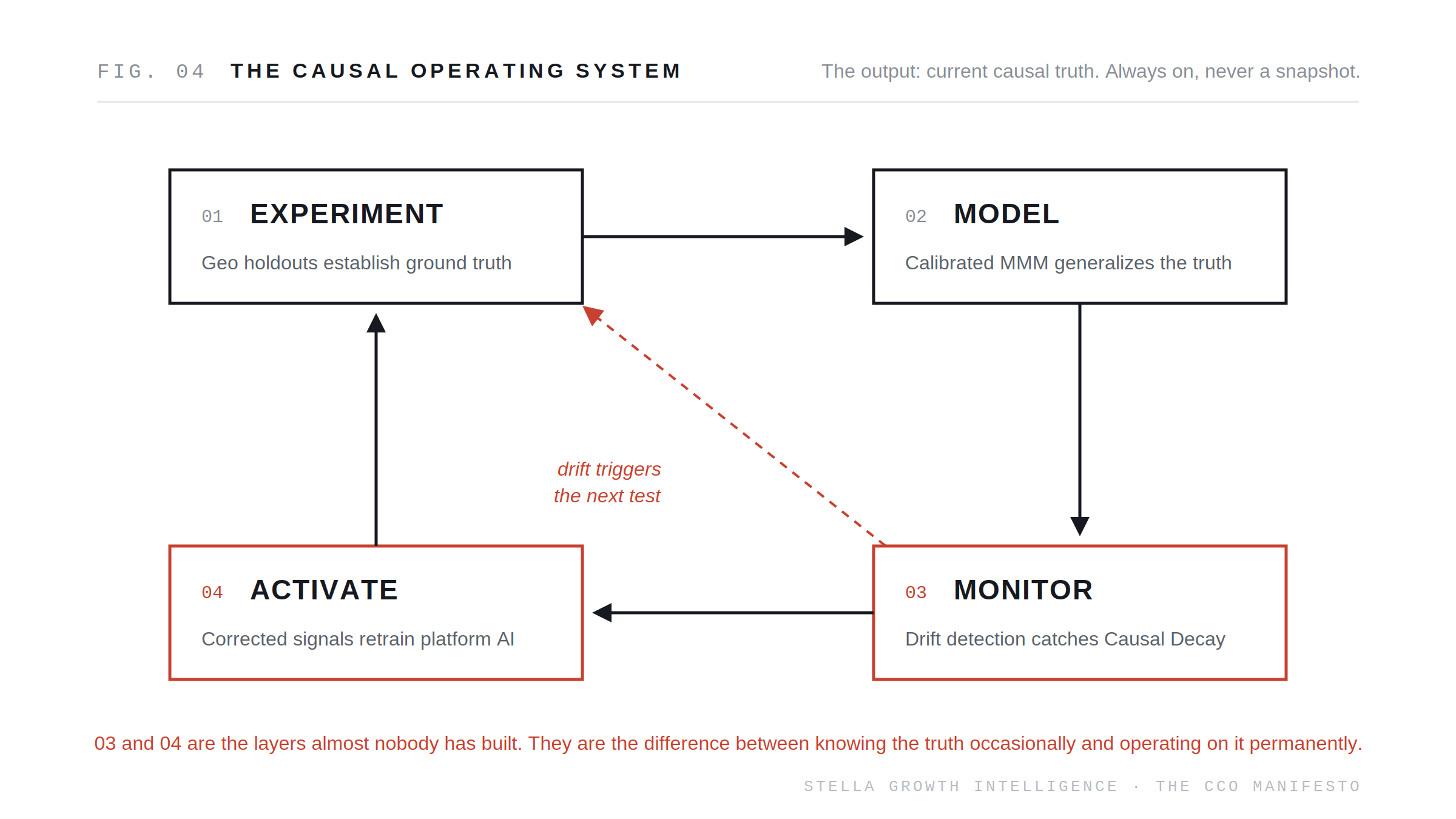
Run any layer alone and you have a product. Run all four as a loop and you have an operating system. Experiments calibrate models. Models extend experiments. Monitoring detects when reality moved. Drift triggers the next experiment. Activation makes all of it touch money.
Each pass through the loop, the system compounds. Better signals produce better platform delivery, which produces cleaner data, which produces better models, which produce better signals. The brand that starts this loop a year before its competitor is not a year ahead. It is a year of compounding ahead, inside an algorithm that rewards the better teacher every single day.
What CCO is not
- Not attribution with better math. No modeling sophistication turns observational touchpoint data into causal truth. The foundation is experimental.
- Not "incrementality testing, but more often." Frequent testing without models, drift detection, and activation is just frequent photography.
- Not an MMM dashboard. An MMM that refreshes monthly and lives in a deck is structural learning with two layers missing and reporting culture doing the rest.
- Not a campaign tactic. CCO does not care what the platforms rename their delivery engines next year. It operates on the input contract every architecture shares.
- Not a replacement for human judgment. It is a replacement for human guessing. Strategy, creative, positioning, and pricing remain human work. CCO makes sure the numbers underneath those decisions are causally true and currently true.
- Not a guarantee of certainty. CCO sharpens posteriors; it does not eliminate uncertainty. Marketing remains an inference problem under conditions of partial observability and shifting underlying dynamics. The framework reduces uncertainty; it does not promise to remove it.
- Not appropriate for every business. The infrastructure cost exceeds the marginal return below a certain scale. Brands spending under approximately $200K/month on paid media, or businesses with short impulse purchase cycles and limited channel diversity, may be better served by simpler approaches. CCO is built for advertisers with enough data volume and channel diversity to identify causal effects.
- Not a finished system. No vendor today fully implements the framework. The most advanced implementations cover three of the four layers; the continuous estimation layer with mature drift detection is still being built across the industry. This document describes where the category is going, not where any single product has already arrived.
What you already have
Category creation should not require demolition. If you run geo holdouts today, you have Layer 1. If you run an MMM, you have Layer 2. If you use Advantage+ or Performance Max, you have part of Layer 4. The two pieces most operators are missing are Layer 3, continuous estimation with drift detection, and the causal signal activation half of Layer 4. Several vendors are building toward these. Some open-source components exist. Most sophisticated brands already own fragments of the system.
Almost none own the two pieces that make it a system. Those two pieces are the difference between knowing the truth occasionally and operating on it permanently.
Where the existing category sits
The framework is also a diagnostic. By scoring categories of vendors against the four layers, the gaps in the existing market become visible. We score categories rather than specific vendors because the strengths and limitations of each category are structural rather than reflecting individual vendor decisions.
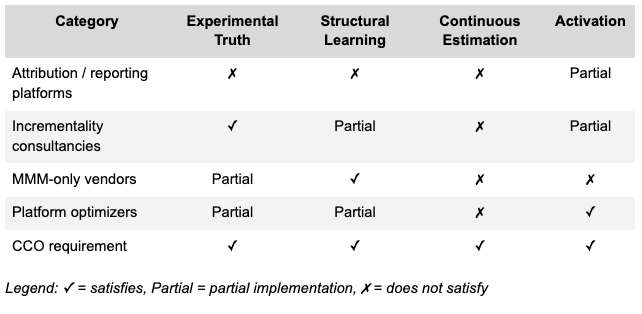
No segment satisfies all four. Reporting tools achieve continuity without causality. Incrementality consultancies achieve causality but run on quarterly cycles. MMM-only vendors deliver strategic causal estimates but disconnect from execution. Platform optimizers execute continuously but train on their own attribution. The category that maps to where marketing decisions are actually going is currently empty.
From ROAS to incremental profit
A brief word on the metric, because the metric is where measurement meets the board room.
Platform ROAS fails the finance test three ways. It is attributed, not caused: a 4.0 platform ROAS that is 40% incremental is a 1.6 causal return wearing a costume. It measures revenue, not profit: an optimizer pointed at revenue will happily scale your least profitable products. And it is average, not marginal: budget decisions happen at the margin, and average ROAS overstates marginal returns on every saturating channel, which is all of them.
The metric that survives all three corrections is incremental contribution margin: the profit, net of variable costs, that a marketing investment causes, which would not have existed without it, evaluated at the marginal dollar.
This is also the metric to send back through the conversions API, because it is the only number that simultaneously satisfies your CFO and trains the algorithm correctly. One number, two audiences, zero translation loss.
When marketing reports attributed ROAS, finance hears an advocacy number and discounts it. When marketing reports experimentally validated incremental contribution margin, marketing spend becomes an investment with a measured, audited return. The brands that make this shift do not win the measurement argument with finance. They dissolve it.
Ten predictions for the next decade of marketing
Frameworks get forgotten. Predictions get argued about. So here are ten, stated plainly enough to be judged wrong later. A few are designed to make some readers angry. Good. Disagree publicly. That's how categories get litigated.
1. By 2030, we expect fewer than 10% of brands to make budget decisions primarily on attribution. Touchpoint data survives as a diagnostic trace, the way web analytics survived after it stopped being mistaken for measurement.
2. Within the decade, we predict budget decisions made from attribution data will come to be viewed the way medicine views bloodletting. Practiced sincerely, by smart people, with great confidence, against the actual interests of the patient. Future marketers will not believe we allocated billions this way.
3. We expect "ROAS optimization" to sound the way "keyword stuffing" sounds now. A phrase that instantly dates the speaker to an era when gaming the measurement was mistaken for doing the marketing.
4. Most agencies charging percentage-of-spend will disappear. The economics of percentage-of-spend agency compensation will come under sustained pressure. The agencies that move to incremental-profit compensation will compete on better terms against those that do not.
5. Incrementality factors will become live operational data, like exchange rates. Dynamic causal multipliers will stream into budget tools and platform APIs the way currency rates stream into treasury systems. A static incrementality number in a quarterly deck will look like a printed stock quote.
6. Every brand will know its Incrementality Half-Lives. "How long does this estimate stay true?" becomes a standard measurement question with a measured answer, channel by channel. Testing calendars die in the same decade, replaced by drift triggers.
7. Signal engineering will become a recognized job title, and the marketing analyst will outrank the media buyer. As the platforms absorb campaign management, the leverage moves to whoever controls what the machines learn. Bid management was a career once too.
8. Every major platform will expose some form of incrementality optimization, and it will deepen the need for independent measurement rather than ending it. They will be late, conflicted, and self-graded, because no platform can be trusted to measure its own counterfactual. The breakdown effect was the preview.
9. In saturated categories, signal quality will become the primary moat. When AI generates everyone's creative and runs everyone's targeting, the brands that survive supplements, skincare, and every other commoditized auction will be the ones whose conversion feeds encode proprietary causal and margin truth the competition cannot copy.
10. A brand with worse creative and a smaller budget will publicly beat a category leader on the same platform, and signal quality will be the documented reason. This is the prediction everything else follows from. Everyone gets the same algorithms. Not everyone teaches them the same things. The companies that win the next decade of marketing will not be the companies with the best attribution. They will be the companies feeding the best causal signals into AI systems.
Who this is for
No marketing organization adopts CCO in a single step. The framework requires capabilities across data, methodology, and execution that are typically built in stages. A useful maturity model has four stages:
Stage 1: Experimental Truth. Geo holdouts running on a regular cadence. At least one causal method producing estimates the organization trusts and acts on. Position-based attribution is no longer the source of truth.
Stage 2: Structural Learning. Calibrated MMM operational. Experimental priors feeding the model. The methods cease to produce independent and contradictory estimates.
Stage 3: Continuous Estimation. Always-on causal monitoring deployed. Drift detection running. The system flags when reality diverges from what the calibrated models predict, and the testing budget starts following uncertainty rather than the calendar.
Stage 4: Activation. Causal truth flows back into the platforms via reverse ETL and conversions APIs. Budget shifts toward marginal incremental contribution within guardrails. The loop closes.
A $10M brand can run Stage 1 manually and reach a functional CCO foundation. A $50M brand adds Stage 2 with calibrated MMM. A $200M+ brand operates the full architecture. The entry point is not a platform purchase; it is the commitment to anchor every causal claim to an experiment, and to treat measurement as infrastructure that runs continuously.
This framework is published openly because categories belong to industries, not to vendors. Brands, agencies, measurement firms, and platforms are all welcome to adopt the vocabulary, score themselves against the four layers, push back on the predictions, or build their own implementations. We will publish deeper treatments of each layer over the coming months, with no gates. The work of building this category is bigger than any single company, and the conversation is more valuable than the marketing.
Why now
Categories are not invented in conference rooms. They are recognized in markets. CRM was not adopted because a vendor named it. It was adopted because Rolodexes and spreadsheets visibly stopped being sufficient.
Marketing is at that threshold now. The old system broke: privacy regulation and platform walls ended reliable attribution. The alternative matured: geo experimentation, Bayesian MMM, and causal inference left academia and became operationally accessible. And the stakes changed: autonomous delivery systems made signal quality the deciding competitive variable, and made stale signals an active liability.
Attribution has visibly stopped being sufficient. Periodic testing has quietly proven insufficient. The shape of what comes next was determined by the shape of the problem.
The closing argument
Attribution failed because it confused correlation with causation.
Static incrementality will fail because it confuses causation with permanence.
The future belongs to the companies that understand three truths: every measurement decays, every market changes, every advantage compounds.
The winners of the next decade will not be the companies that discover causal truth.
They will be the companies that continuously rediscover it.
Static incrementality is dead. Build the loop.
Continuous Causal Optimization is offered openly to the marketing measurement industry. The author is co-founder of Stella, one of several vendors building toward this architecture. The framework is not claimed by any single vendor and is published without restriction.
Bibliography
[1] Blake, T., Nosko, C., and Tadelis, S. "Consumer Heterogeneity and Paid Search Effectiveness: A Large-Scale Field Experiment." Econometrica, 83(1), 2015, pp. 155–174.
[2] Gordon, B. R., Zettelmeyer, F., Bhargava, N., and Chapsky, D. "A Comparison of Approaches to Advertising Measurement: Evidence from Big Field Experiments at Facebook." Marketing Science, 38(2), 2019, pp. 193–225.
[3] Lee, R., et al. "Meta Andromeda: Supercharging Advantage+ automation with the next-gen personalized ads retrieval engine." Meta Engineering Blog, December 2, 2024. https://engineering.fb.com/2024/12/02/production-engineering/meta-andromeda-advantage-automation-next-gen-personalized-ads-retrieval-engine/
[4] Meta. "AI Innovation in Meta's Ads Ranking Driving Advertiser Performance." Meta for Business, 2024. https://www.facebook.com/business/news/ai-innovation-in-metas-ads-ranking-driving-advertiser-performance
[5] Meta. "Meta's Generative Ads Model (GEM): The Central Brain Accelerating Ads Recommendation AI Innovation." Meta Engineering Blog, November 10, 2025. https://engineering.fb.com/2025/11/10/ml-applications/metas-generative-ads-model-gem-the-central-brain-accelerating-ads-recommendation-ai-innovation/
[6] Meta. "Meta Adaptive Ranking Model: Bending the Inference Scaling Curve to Serve LLM-Scale Models for Ads." Meta Engineering Blog, March 31, 2026. https://engineering.fb.com/2026/03/31/ml-applications/meta-adaptive-ranking-model-bending-the-inference-scaling-curve-to-serve-llm-scale-models-for-ads/
[7] Meta for Business. "About the breakdown effect." Meta for Business Help Center.
[8] Thompson, B. "An Interview with Mark Zuckerberg." Stratechery, May 2025.
[9] Abadie, A., Diamond, A., and Hainmueller, J. "Synthetic control methods for comparative case studies: Estimating the effect of California's tobacco control program." Journal of the American Statistical Association, 105(490), 2010, pp. 493–505.
[10] Jin, Y., Wang, Y., Sun, Y., Chan, D., and Koehler, J. "Bayesian methods for media mix modeling with carryover and shape effects." Google Inc., 2017.
[11] Chan, D., and Perry, M. "Challenges and opportunities in media mix modeling." Google Research, 2017.
[12] Brodersen, K. H., Gallusser, F., Koehler, J., Remy, N., and Scott, S. L. "Inferring causal impact using Bayesian structural time-series models." The Annals of Applied Statistics, 9(1), 2015, pp. 247–274.